爬山虎采集器官方版
下载地址
下载地址


本地下载文件大小:15.5MB
第一步:打开客户端,选择简易模式
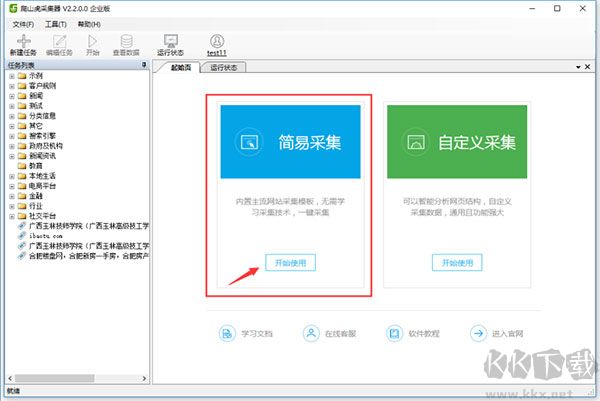
选择相应的采集模板
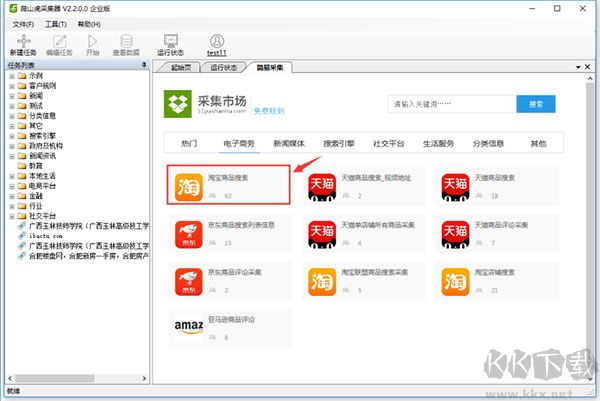
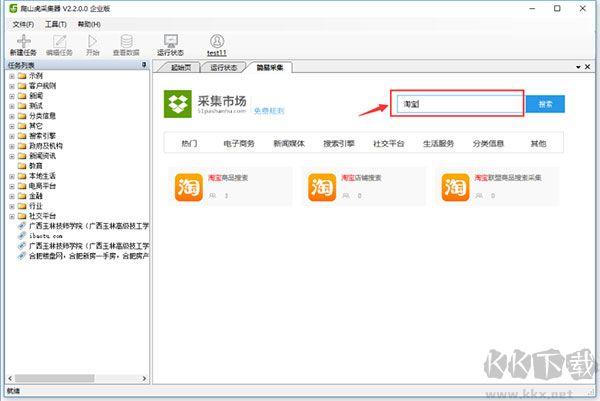
也可以根据入关键词搜索,筛选对应的模板分类
第二步:预览模板的采集字段和示例数据
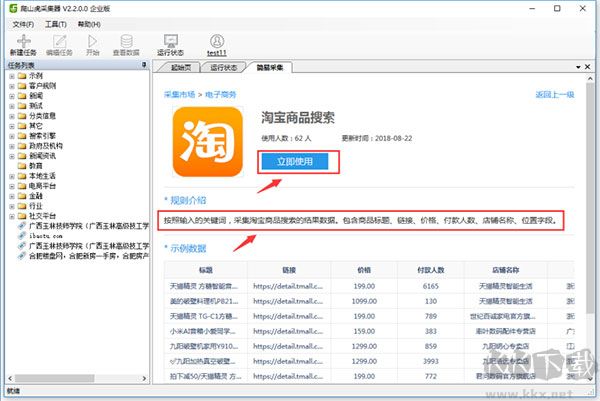
根据提示,输入对应的参数(此模板是输入需要采集的关键词)
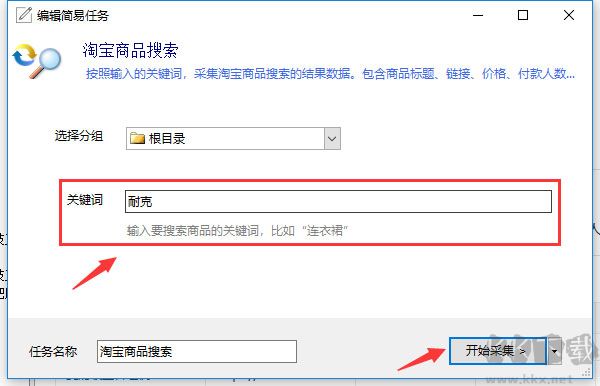
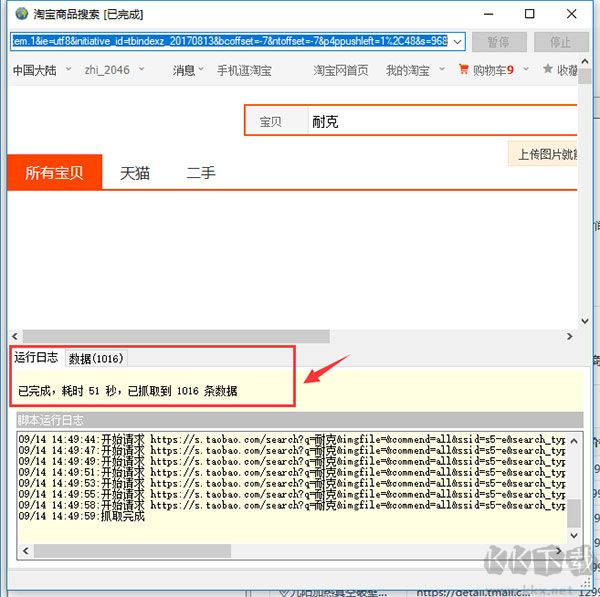
第三步:运行并下载
开始即可查看加载的进程
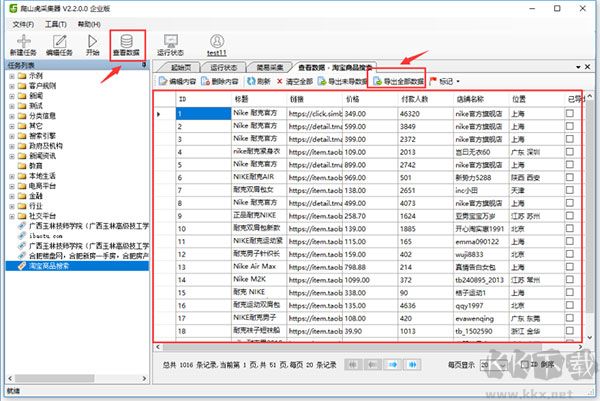
任务列表中:选中任务/点击查看
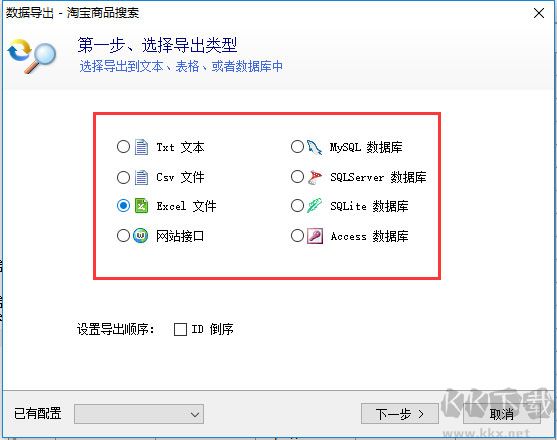
选择合适的保存格式
1、向导模式
操作简便,通过鼠标点选即可自动生成采集脚本。
2、定时运行
可按设定时间自动执行任务,无需人工值守。
3、独创高速内核
自研浏览器引擎,处理速度较快,性能优于同类产品。
4、智能识别
能自动判断网页中的列表、表单结构(如多选框、下拉列表等)。
5、广告屏蔽
内置定制化广告过滤模块,兼容AdblockPlus规则,支持用户自定义过滤条件。
6、多种数据导出
支持导出至Txt、Excel、MySQL、SQLServer、SQlite、Access及网站等多种格式或平台。
1、上手容易,通过可视化操作界面,用鼠标点击就能完成数据采集,采用向导式流程,用户无需技术基础,输入网址后一键提取内容,对编程零基础的用户非常友好。
2、依靠自主研发的智能识别算法,可自动判断列表数据和分页信息,准确率高达95%。支持深入采集多层页面,快速精确地获取所需内容。
3、新一代智能爬虫工具学习门槛低,结合智能算法与可视化界面,内置大量模板,用户只需简单设置并点击鼠标,即可完成数据采集任务。
4、适用性强,能覆盖99%的网站类型,包括静态页面、动态页面、单页应用及移动端应用,同时支持数据的获取与提交操作。
5、内置丰富多样的网站采集模板,覆盖多个不同领域。选择模板加载数据后,经过简单配置就能迅速获得准确信息,满足多种采集场景需求。
问:怎样跳过列表中的前N条数据?
1、有时候需要排除采集结果中的前几项,例如在抓取表格时,去掉表头那一行。
2、点击列表模式菜单中的“设置列表xpath”选项进行配置。
问:如何抓取Cookie并手动配置?
1、用谷歌浏览器打开目标网站,并完成登录操作。
2、按F12键调出开发者工具,切换到Network选项卡。
3、按F5刷新页面,从列表中选择一个网络请求。
4、复制所需的Cookie信息后,在爬山虎采集器中编辑任务,进入第三步,设置HTTP Header。
v5.0.2.5版本
解决部分网站卡死问题;
增加分组的运行历史;
性能提升;
优化OCR功能;
修复其他问题。
爬山虎采集器官方版 v5.0.2.5电脑版15.5MB返回顶部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下载站是专业的免费软件下载站点,提供绿色软件、免费软件,手机软件,系统软件,单机游戏等热门资源安全下载!
本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知

 超级弱口令检查工具 v1.0.20190522 绿色免安装版
超级弱口令检查工具 v1.0.20190522 绿色免安装版 GX Developer V8.86绿色破解版
GX Developer V8.86绿色破解版 PE Explorer可视化汉化集成工具 V1.99 R6绿色汉化版
PE Explorer可视化汉化集成工具 V1.99 R6绿色汉化版 图吧工具箱最新版 v2.0官方版
图吧工具箱最新版 v2.0官方版 C-Lodop云打印服务器 v4.127电脑版
C-Lodop云打印服务器 v4.127电脑版 MongoChef v5.0.3 中文破解版
MongoChef v5.0.3 中文破解版 DXF Works(DXF文件数据提取工具) v4.6官方破解版
DXF Works(DXF文件数据提取工具) v4.6官方破解版 电子贺卡软件(Greeting Card Studio) v6.11 绿色版
电子贺卡软件(Greeting Card Studio) v6.11 绿色版