下载君(高清美女图片批量下载器)
下载地址
下载地址
")

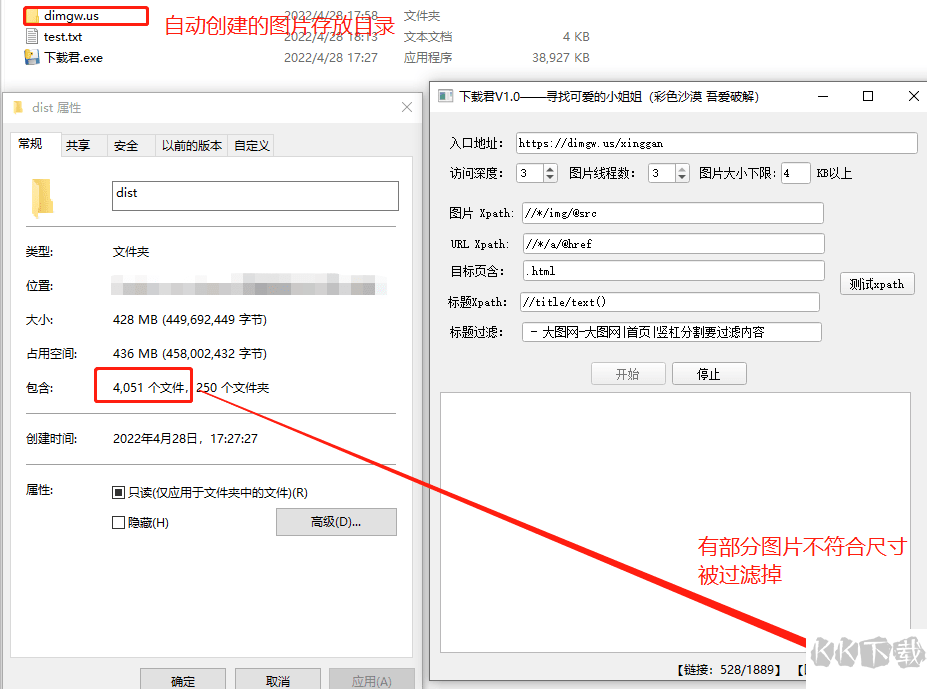
本地下载文件大小:38M
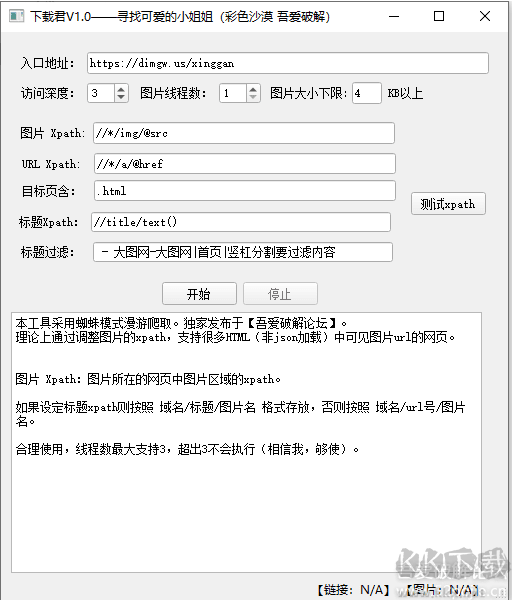

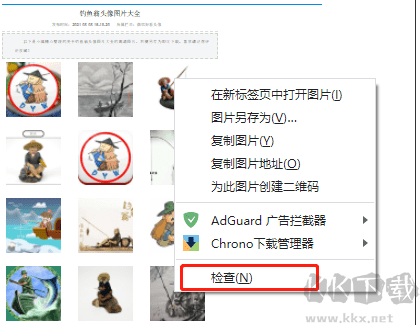
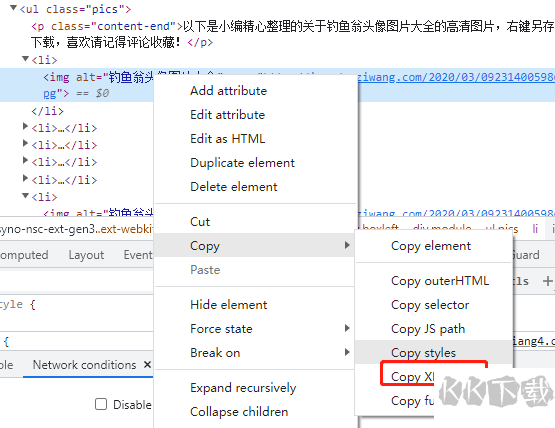
//*[@id="syno-nsc-ext-gen3"]/div[3]/div[3]/div[1]/div[1]/ul/li[7]/img

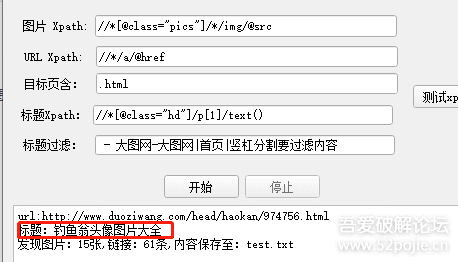
//*[@class="pics"]/*/img
//*[@class="pics"]/*/img/@src
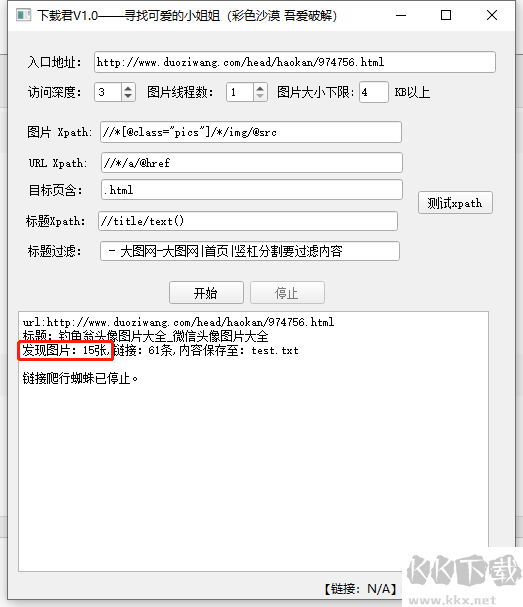
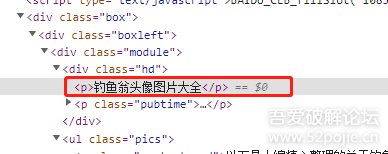
//*[@class="hd"]/p[1]/text()
返回顶部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下载站是专业的免费软件下载站点,提供绿色软件、免费软件,手机软件,系统软件,单机游戏等热门资源安全下载!
本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知
 迅雷地址转换工具 V4.0绿色版
迅雷地址转换工具 V4.0绿色版 快车(FlashGet) v3.7.0.1
快车(FlashGet) v3.7.0.1 迅雷下载器 v11.4.3.2054
迅雷下载器 v11.4.3.2054 城通网盘 v3.59PC版
城通网盘 v3.59PC版 Mipony网盘资源下载工具 v3.3.1绿色版
Mipony网盘资源下载工具 v3.3.1绿色版 闪豆视频下载器20233.7.0 最新版
闪豆视频下载器20233.7.0 最新版  Internet Download Manager下载神器 V7.0中文绿色特别版
Internet Download Manager下载神器 V7.0中文绿色特别版 电驴(VeryCD) v1.2.2绿色版
电驴(VeryCD) v1.2.2绿色版