Umiocr(识别工具)
下载地址
下载地址
")

本地下载文件大小:98.5MB
Umiocr(识别工具)是一款免费开源的OCR软件,解压就可以使用,不需要联网。内置高效OCR引擎,可以从图片和文档中批量提取文字,还能读取二维码内容、输入文字生成二维码。软件支持命令行与HTTP接口调用,具备多语言识别能力,可以满足不同场景的文字提取需求,适用于日常文字提取、批量文档处理,以及开发者、技术用户等各类人群。需要的朋友快来下载试试吧!
1、下载后双击【Umi-OCR_Rapid_v2.1.5.7z.exe】,软件发布包下载为 .7z 压缩包或 .7z.exe 自解压包。自解压包可在没有安装压缩软件的电脑上,解压文件。

2、选择一个解压路径,点击【Extract】,等待一会。
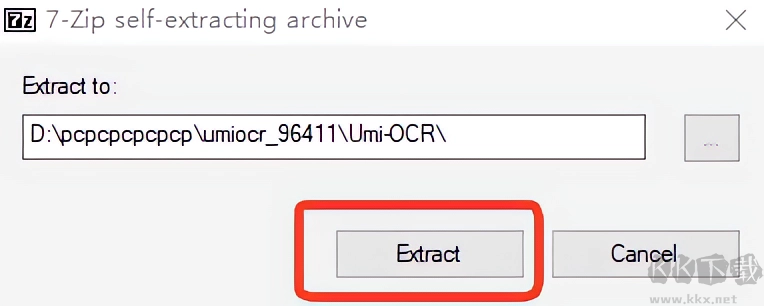
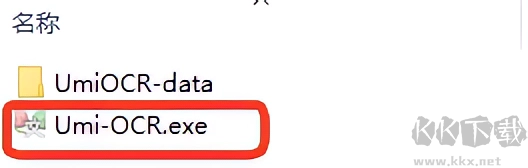
3、之后就会出现一个【Umi-OCR_Rapid_v2.1.5】的文件夹,点击进去后双击【Umi-OCR.exe】即可启动。

4、点击进去后双击【Umi-OCR.exe】即可启动。
1、免费:本项目采用完全开源模式,所有源代码公开,用户可自由使用、修改和分发,无任何费用或隐藏限制。
2、方便:软件为绿色便携版,解压后即可直接运行,无需安装,且全程支持离线操作,不依赖网络连接,保障隐私与使用稳定性。
3、高效:内置高性能离线OCR引擎,识别速度快、准确率高,并预集成多国语言识别库,涵盖中文、英文、日文、韩文等主流语种,满足多样化文本提取需求。
4、灵活:除图形界面外,还提供命令行调用和HTTP API接口,便于集成到自动化脚本、第三方应用或工作流系统中,扩展性强。
5、功能全面:支持多种实用场景,包括屏幕截图OCR、批量图片文字识别、PDF文档内容提取、二维码扫描解析,以及数学公式识别等,覆盖学习、办公与开发等多种用途。
1、普通用户:希望快速从屏幕截图或本地图片中提取文字内容,注重隐私安全,不愿将敏感信息上传至网络服务。
2、批量文档处理人员:面对大量图片或 PDF 文件,需高效、批量地将其转换为可编辑文本格式,如 TXT、CSV、Markdown(MD)等,用于归档、分析或再利用。
3、多语言及扫码需求者:需要识别包含中文、英文、日文、韩文等多种语言的文本,或频繁处理条形码、二维码的扫描与内容解析,适用于跨境办公、物流、教育等场景。
v2.1.5版本
1、新增:日志机制。在命令行中启动 Umi-OCR 可查看实时日志。指定级别以上(默认为ERROR)的日志被保存到 Umi-OCR/UmiOCR-data/logs 目录中,保存级别可以在全局设置标签页中更改。
2、新增:大部分标签页能手动切换左右/上下双栏模式。
3、新增:Esc键隐藏主窗口。
4、新增:调整二维码生成相关参数后,自动刷新二维码生成。
5、新增:命令行指令 --reload ,用于重新加载配置文件。
6、修复:文档识别提取PDF自带的文本内容时,未考虑页面旋转的影响。
7、修复:文档识别生成单层PDF时,未写入原PDF自带的文本内容。
8、修复:OCR结果展示列表的一些显示Bug和鼠标划选Bug。
9、修复:调整标签页顺序或删除标签页后,未及时保存顺序信息。
10、修复:HTTP接口 /api/doc/download 参数 ignore_blank 的错误。
11、修复:Linux版本截图时,系统任务栏推移顶层窗口,导致截图位置偏移。
12、修复:Linux版本截图后,主窗口的位置与操作前不一致。
13、优化:图片/文档的异步加载机制。现在可以流畅地加载含有数万个子文件的文件夹,且能预览加载进度。
14、Windows 版本更新第三方依赖库:PyMuPDF 1.24.11 ,fontTools 4.56.0 ,Pillow 10.4.0 ,psutil 10.4.0 ,pynput 1.8.0 ,zxing-cpp 2.3.0
15、新增UI语言:俄语 Русский ,译者:Вячеслав Анатольевич Малышев、Muhammadyusuf Kurbonov。泰米尔语 தமிழ் ,译者:தமிழ்நேரம்。
Umiocr(识别工具) v2.1.5电脑版98.5MB返回顶部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下载站是专业的免费软件下载站点,提供绿色软件、免费软件,手机软件,系统软件,单机游戏等热门资源安全下载!
本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知

 笔神写作 v3.1.12官方版
笔神写作 v3.1.12官方版 李旭科毛笔字体
李旭科毛笔字体  vim编辑器 v8.2.1009单文件绿色版
vim编辑器 v8.2.1009单文件绿色版 复古大字报字体 v4.1免费版
复古大字报字体 v4.1免费版 捷速OCR文字识别 v7.5.8.3PC版
捷速OCR文字识别 v7.5.8.3PC版 建行儒黑中字体 V1.0官方版
建行儒黑中字体 V1.0官方版 识字体客户端 v2.0.0 官方最新版
识字体客户端 v2.0.0 官方最新版 Insofta 3D Text Commander官方2024最新版 v6.5.0
Insofta 3D Text Commander官方2024最新版 v6.5.0