转转大师ocr文字识别软件
下载地址
下载地址


本地下载文件大小:29.84MB
转转大师ocr文字识别软件是一款提供高效精准文档识别、数据提取功能的服务工具。作为国内知名 OCR文字识别工具,它识别率较高,支持多国字符和彩色文件识别,主要用于将扫描图像、图片型 PDF 转化为可编辑文本,目前能精准识别 JPG、GIF、PNG、BMP、TIF、PDF 等格式,非常强大。需要的朋友快来下载试试吧!
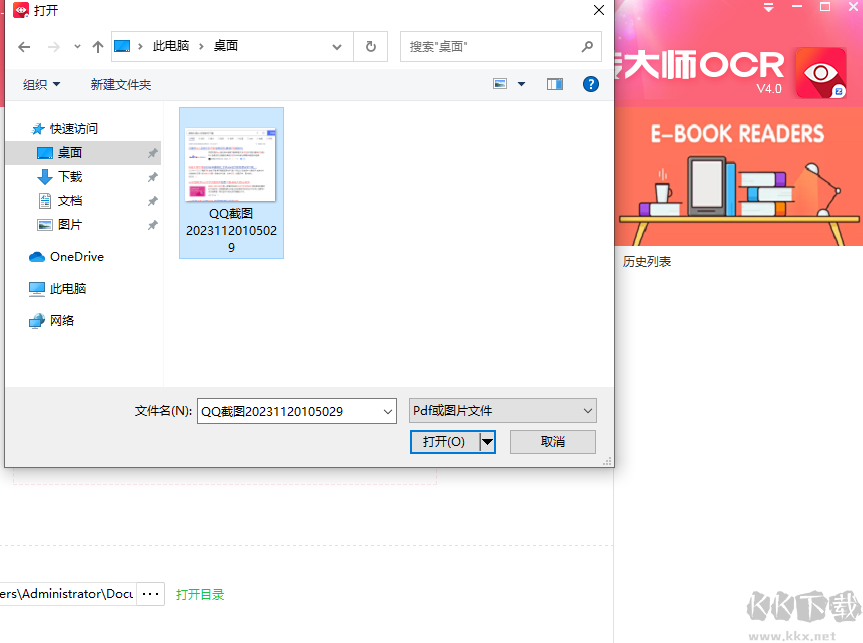
1、安装完成之后,运行软件,我们可以将PDF或者图片文件拖入到软件中
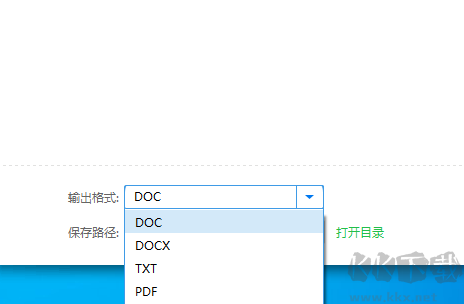
2、然后选择输出格式,点击转换即可
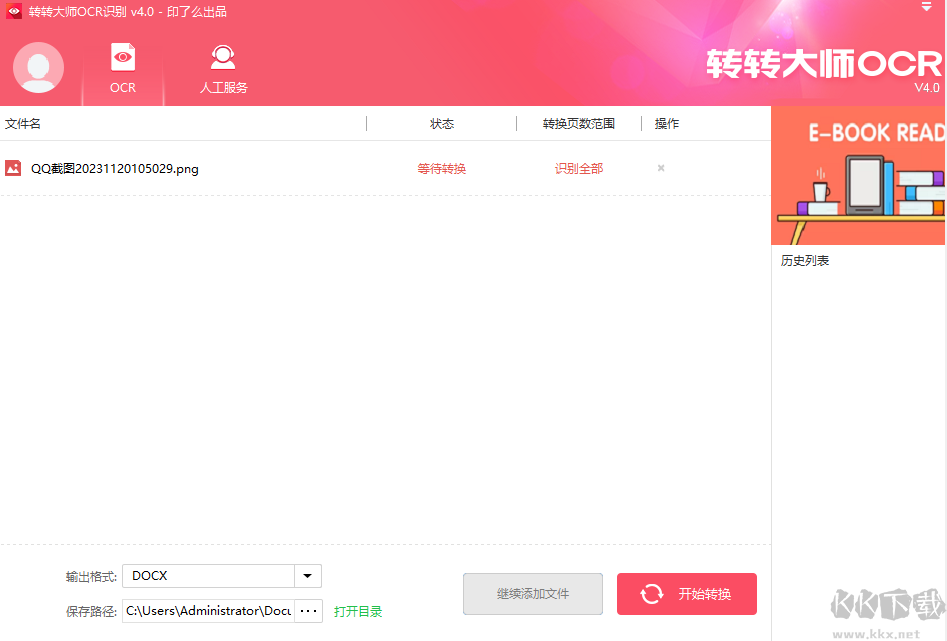
3、等待转换进度完成即可
1、卡片类识别
可快速准确地提取证件信息,也能识别各类卡片内容,采用通用OCR技术,支持营业执照或任意版面的通用文字识别。
2、证件类识别
适配多种实际应用场景,能够处理复杂背景或不规则排版的图像,实现文字信息的高效提取,适用于各类印刷材料的识别需求。
3、识别准确性
依托先进的深度学习算法,结合大量样本数据,经过长期优化训练,实现图像中文字的高精度识别,识别准确率处于行业前列。
4、转换效率高
核心功能只需简单拖拽操作,即可将PDF文件与图片转换为可编辑的PDF、DOC、HTML及TXT等多种格式,提升文档处理效率。
5、性能稳定
软件持续优化更新,后台服务运行稳定,响应及时,具备大容量存储能力,网络连接顺畅,保障服务长期可靠运行。
一、为什么转换后的Word是由图片组成的?
这表明您的PDF文件实际上是由嵌入的文字图片构成,而非实际的文本内容。因此,转换后得到的Word文件也包含了这些图片而非可编辑的文字。
二、为什么转换出来的文件打不开?
通常这种情况是由于文件格式的问题,请尝试使用Word 2003、2007或2010版本来打开转换后的文件。此外,如果文件体积较大,可能会导致打开速度变慢,建议稍作等待再尝试打开。
三、为什么转换后的Word会出现乱码?
当PDF中含有复杂的科学公式、罕见语言文字或特殊字符时,这可能导致转换软件无法正确识别并转换这些内容,从而产生乱码。在这些情况下,无论尝试多少次转换,结果往往相同。
v4.0.0.0版本
1、修改pdf转word内核
2、修复数据统计错误
转转大师ocr文字识别软件 v4.0.0.029.84MB返回顶部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下载站是专业的免费软件下载站点,提供绿色软件、免费软件,手机软件,系统软件,单机游戏等热门资源安全下载!
本站资源均收集整理于互联网,其著作权归原作者所有,如果有侵犯您权利的资源,请来信告知

 易媒助手破解版 v2.1.0
易媒助手破解版 v2.1.0 免费的语音合成/语音识别软件 v2.1绿色免费
免费的语音合成/语音识别软件 v2.1绿色免费 Typora(Markdown编辑器) v1.9.5
Typora(Markdown编辑器) v1.9.5 高级文本编辑器(PilotEdit Lite) 14.0.0中文绿色版
高级文本编辑器(PilotEdit Lite) 14.0.0中文绿色版 汉王OCR v6.0破解版
汉王OCR v6.0破解版 时尚Bleeding Cowboys字体
时尚Bleeding Cowboys字体  识字体客户端 v1.3.0官方最新版
识字体客户端 v1.3.0官方最新版 abbyy finereader 11 v11.0.113.164电脑版
abbyy finereader 11 v11.0.113.164电脑版